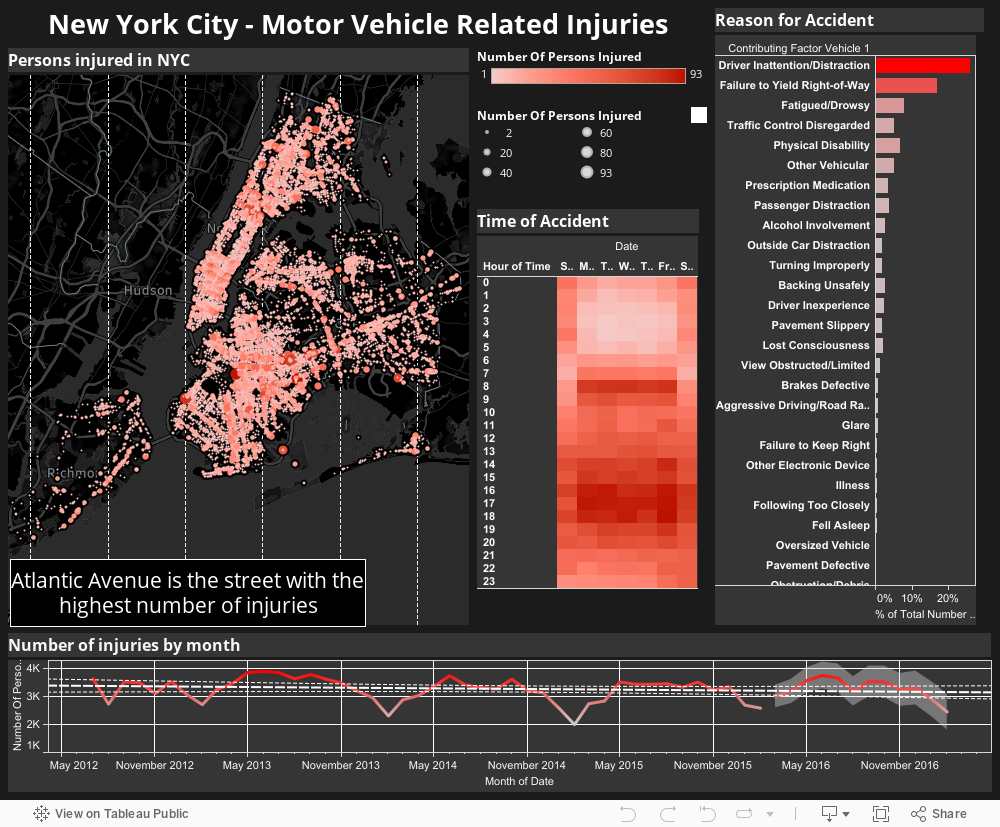
Goal
Since Bill de Blasio has taken office in 2013 one of his missions for his mayorship of New York City is to reduce the number of traffic-related injuries and fatalities in his "Vision Zero" campaign. An ambitious campaign to reach zero traffic injuries. I analyze data provided by NYC (you can dowload the dataset here), in order to determine whether the campaign was successful in reducing the number of traffic-releated injuries.