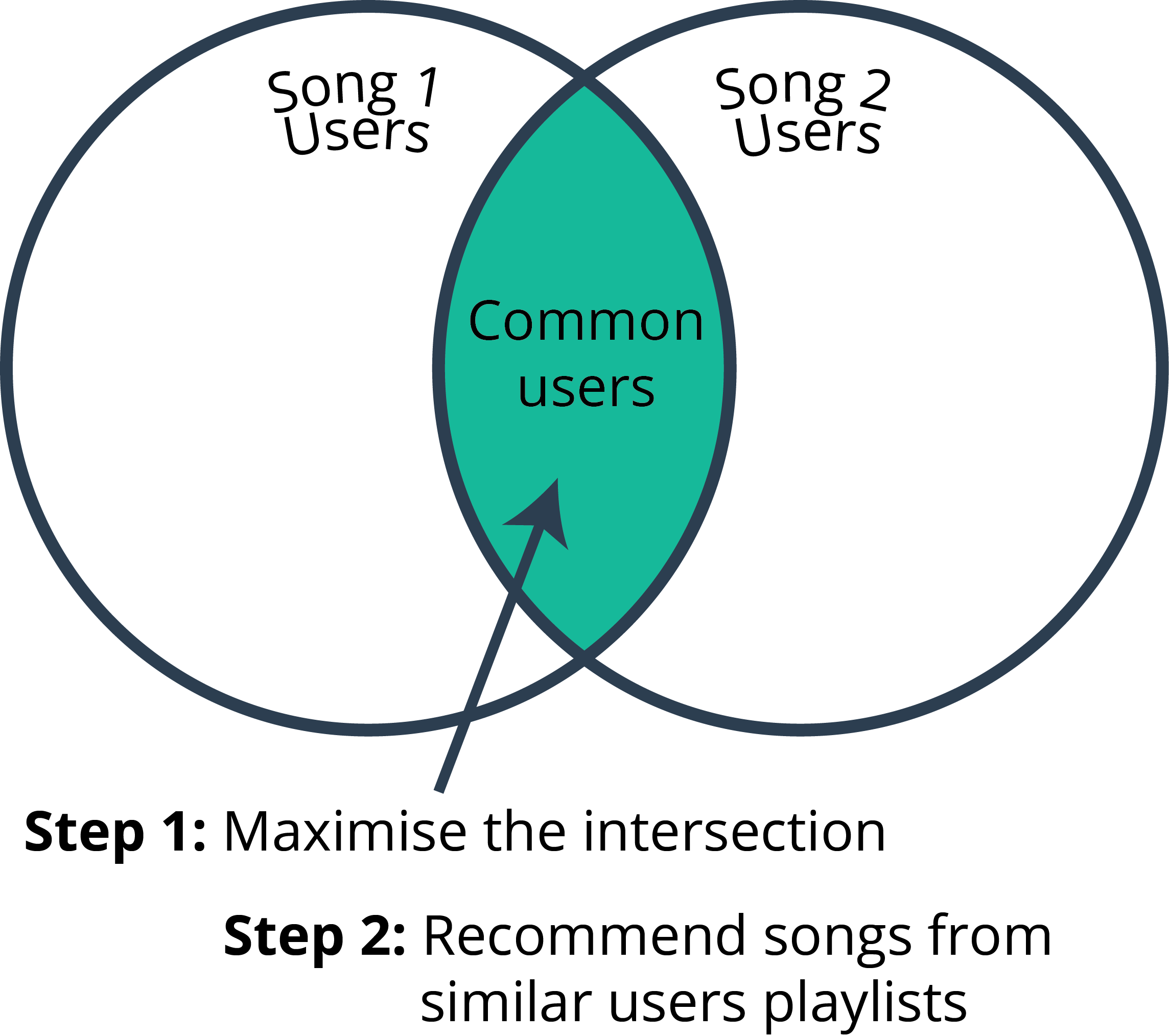
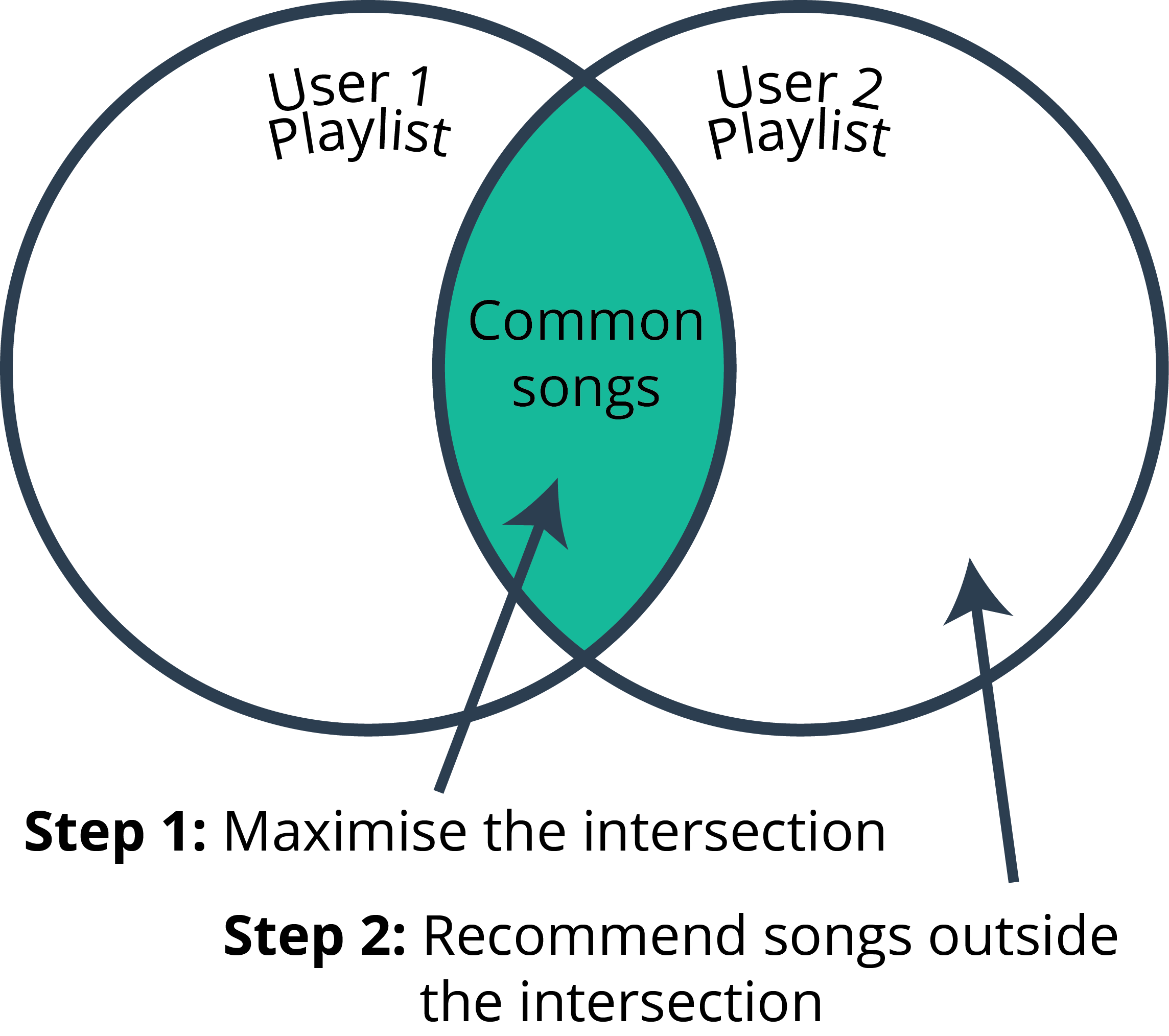
Goal
The goal is to build a music recommendation system that can provide custom playlists for individual users based on collaborative and metadata filtering. Currently music service providers have generic (and popular), mood-based playlists, that are the same for all users. Here, I suggest improvements to these playlists by offering custom options for each user based on song metadata.
The complete code can be found on github here.