Hypothesize
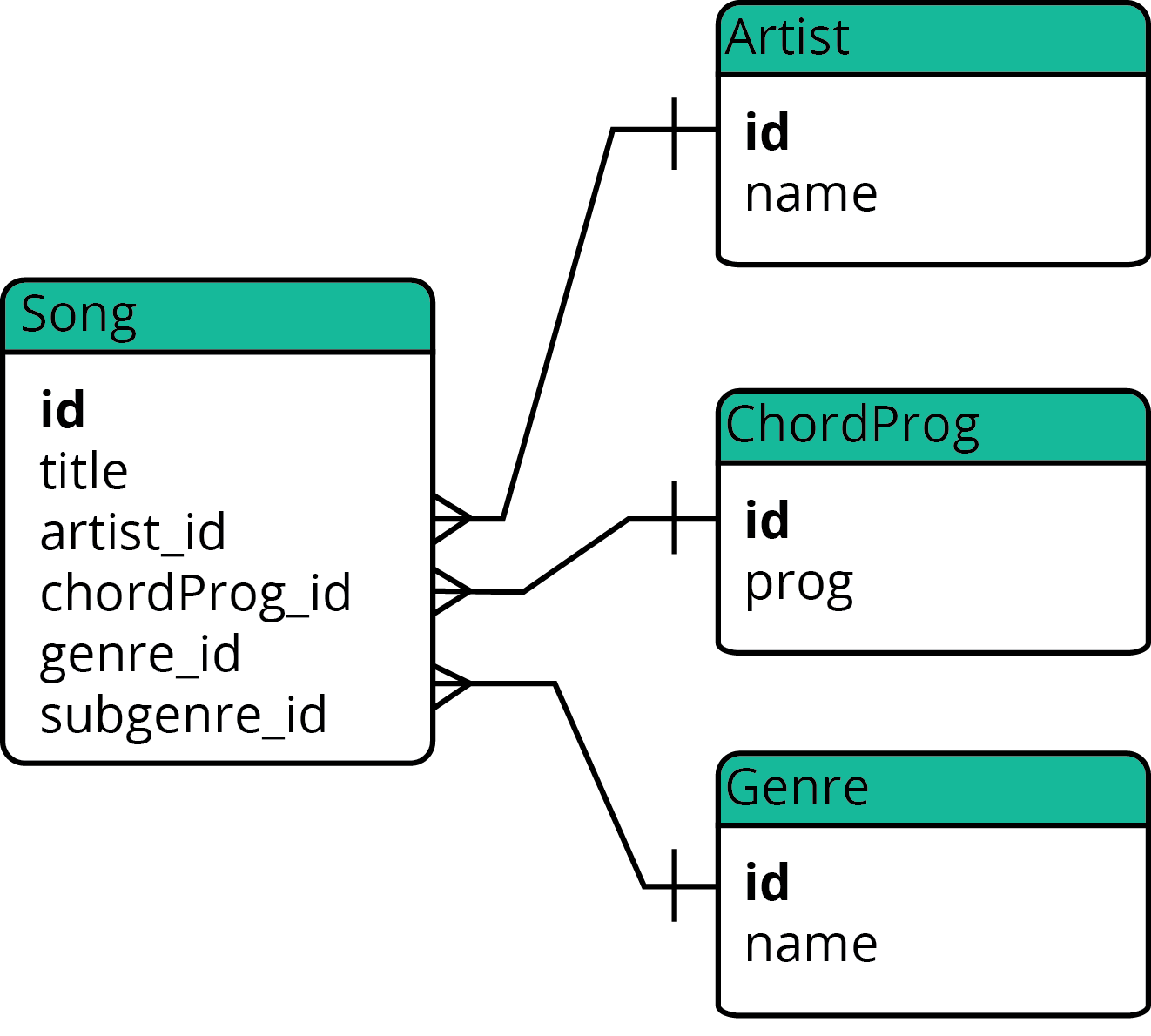
I hypothesize that all country music sounds the same because of similiarities in the components of songs. Specifically, because many country music songs are composed with vocals and guitar, the way the guitar is played and the kinds of lyrics used in the songs may be key components in determining whether or not all country music does sound similar. The way the guitar is played can be determined by the chord progression, and I hypothesize that many country songs all use the same chord progession, whereas in other genres of music, there will be a greater variation of the chord progressions used in songs. I also suspect that the lyrics have some similarity in the words used and a naive-Bayes analysis may be suitable.
The complete code can be found on github here.